MLBiNet: A Cross-Sentence Collective Event Detection Network
跨句子问题的解决关键在于:编码语义信息,在文档级去建模事件的相互依赖关系。具体地说,我们首先设计了一个双向解码器,在解码事件标记向量序列时,模拟一个句子内的事件相互依赖关系。其次,利用信息聚合模块对句子级语义信息和事件标签信息进行聚合。最后,我们将多个双向译码器堆叠起来,并提供跨句信息,形成多层双向标签结构,实现信息在句子间的迭代传播。
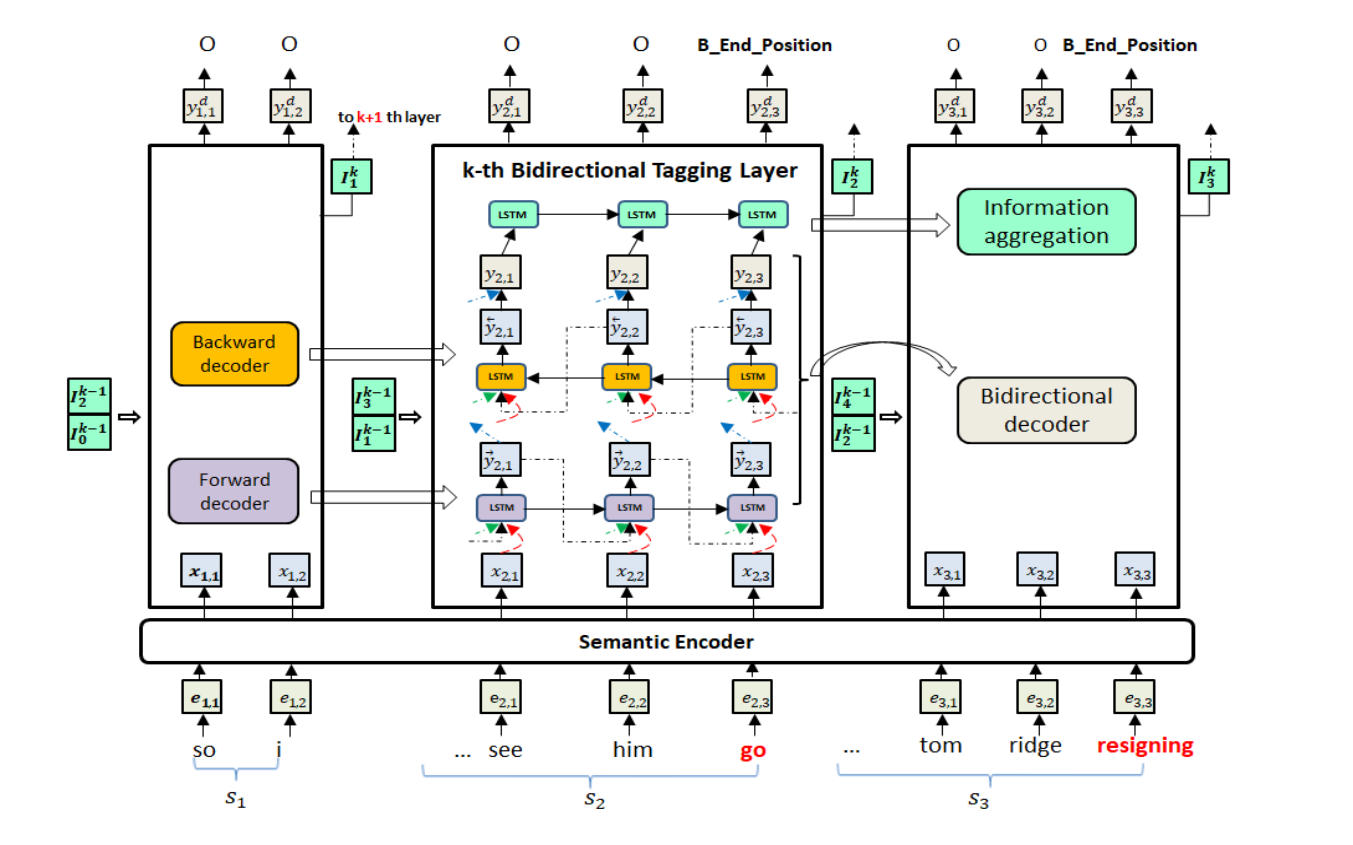
Seq2Seq 多层双向网络 捕捉多个不同事件。四个部分:语义编码器、双向解码器、信息聚合模块、堆叠式多元双向标记层
用 attention-RNN 作为主要的架构
a) 独立的编码器模块在融合句子级和文档级语义信息方面具有灵活性;
b) RNN解码器模型的上下文向量和当前状态的学习捕捉:可以捕获序列事件标签相关性,将预测的标签向量作为预测 t 符号的输入
事件抽取和一般 RNN 的区别
事件抽取中生成序列长度是已知的,与原始序列一致。
ED任务解码器的词汇表不是单词,而是事件类型的集合
语义编码器
对 word 和 NER type 分别做 embedding,将两个信息拼接起来,每个 token 有了可理解的表征 \mathbf e_t。
用 Skip-gram 预训练 word。在训练过程中对NER型嵌入矩阵进行随机初始化和更新。
利用双向LSTM和自注意机制对每个标记的句子级上下文信息进行编码,也就是每次按句子训练。
word embedding + NER type embedding -> e_t
LSTM + self-attn ->h_t^a
对于每个 word:
\mathbf x_t = [\mathbf h_t^a; \mathbf e_t]相当于是 skip-connection
双向解码器
事件抽取中生成序列长度是已知的,与原始序列一致。用双向编码器,模拟句子间的关系。
前向解码
\begin{gathered}
\overrightarrow{\mathbf{s}}_{t}=f_{\mathrm{fw}}\left(\overrightarrow{\mathbf{y}}_{t-1}, \overrightarrow{\mathbf{s}}_{t-1}, \mathbf{x}_{t}\right) \\
\overrightarrow{\mathbf{y}}_{t}=\tilde{f}\left(W_{y} \overrightarrow{\mathbf{s}}_{t}+b_{y}\right)
\end{gathered}后向解码
\begin{gathered}
\overleftarrow{\mathrm{s}}_{t}=f_{\mathrm{bw}}\left(\overleftarrow{\mathbf{y}}_{t+1}, \overleftarrow{\mathrm{s}}_{t+1}, \mathrm{x}_{t}\right) \\
\overleftarrow{\mathbf{y}}_{t}=\tilde{f}\left(W_{y} \overleftarrow{\mathrm{s}}_{t}+b_{y}\right)
\end{gathered}双向解码
双向解码器通过组合 forward 和 backward 解码器立即模拟事件相互依赖性。垂直标记层利用了两个向前的参数和标签注意机制来捕获双向的事件依赖。
信息聚合
对于当前句子,我们关注的信息可以总结为记录哪些实体和令牌触发哪些事件。因此,为了总结信息,我们使用事件标签向量 \mathbf y_t 作为输入,设计与事件标签向量 \mathbf y_t 的LSTM层(图1中所示的信息聚合模型)。
\tilde{\mathbf{I}}_{t}=\overrightarrow{\operatorname{LSTM}}\left(\tilde{\mathbf{I}}_{t-1}, \mathbf{y}_{t}\right)最后的向量 \tilde{\mathbf I}_{ni} 作为总结向量。
句子级的信息聚合模块架起了跨句信息的桥梁,形式化的信息很容易集成到其他句子的解码过程中,增强了事件相关信息。
多层双向网络
在该模块中,我们将多个双向标记层堆叠机制,以在双向解码器中聚集相邻句子的信息,并在句子中传播信息。由双向解码器层和信息聚合模块录制的信息 (\{\mathbf y_t \}, \mathbf I_i) 已捕获句子中的事件相关信息。但是,跨句子信息尚未互动。对于给定的句子,正如我们在表1中所看到的那样,其相关信息主要存储在邻近的句子中,而遥远的句子很少相关。因此,我们建议在相邻句子中传输总结句子信息 \mathbf I_i。
由双向解码器层和信息聚合模块录制的信息 (\{\mathbf y_t \}, \mathbf I_i) 捕获句子中的事件相关信息。但是,跨句子信息尚未获取。
可以通过将输入扩展为\mathbf I_{i-1}和 \mathbf I_{i+1} 来形成跨句子信息。 k 是层数。
\begin{gathered}
\overrightarrow{\mathbf{s}}_{t}=f_{\mathrm{fw}}\left(\overrightarrow{\mathbf{y}}_{t-1}^{k}, \overrightarrow{\mathbf{s}}_{t-1}, \mathbf{x}_{t}, \mathbf{I}_{i-1}^{k-1}, \mathbf{I}_{i+1}^{k-1}\right) \\
\overleftarrow{\mathbf{s}}_{t}=f_{\mathrm{bw}}\left(\overleftarrow{\mathbf{y}}_{t+1}, \overleftarrow{\mathbf{s}}_{t+1}, \mathbf{x}_{t}, \mathbf{I}_{i-1}^{k-1}, \mathbf{I}_{i+1}^{k-1}\right) \\
\overrightarrow{\mathbf{y}}_{t}^{k}=\tilde{f}\left(W_{y} \overrightarrow{\mathbf{s}}_{t}+b_{y}\right) \\
\overleftarrow{\mathbf{y}}_{t}^{k}=\tilde{f}\left(W_{y} \overleftarrow{\mathbf{s}}_{t}+b_{y}\right) \\
\mathbf{y}_{t}^{k}=\left[\overrightarrow{\mathbf{y}}_{t}^{k} ; \overleftarrow{\mathbf{y}}_{t}^{k}\right]
\end{gathered}